
这是一个创建于 1937 天前的主题,其中的信息可能已经有所发展或是发生改变。
项目起源
开发这个项目,源自于我在知网发现了一篇关于自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》
这篇论文中描述的算法看起来简洁清晰,并且符合逻辑。但由于论文中只讲了算法原理,并没有具体的语言实现,所以我使用 Python 根据论文实现了这个抽取器。并分别使用今日头条、网易新闻、游民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻做了测试,发现提取效果非常出色,几乎能够达到 100%的准确率。
项目现状
在论文中描述的正文提取基础上,我增加了标题、发布时间和文章作者的自动化探测与提取功能。
最后的输出效果如下图所示:
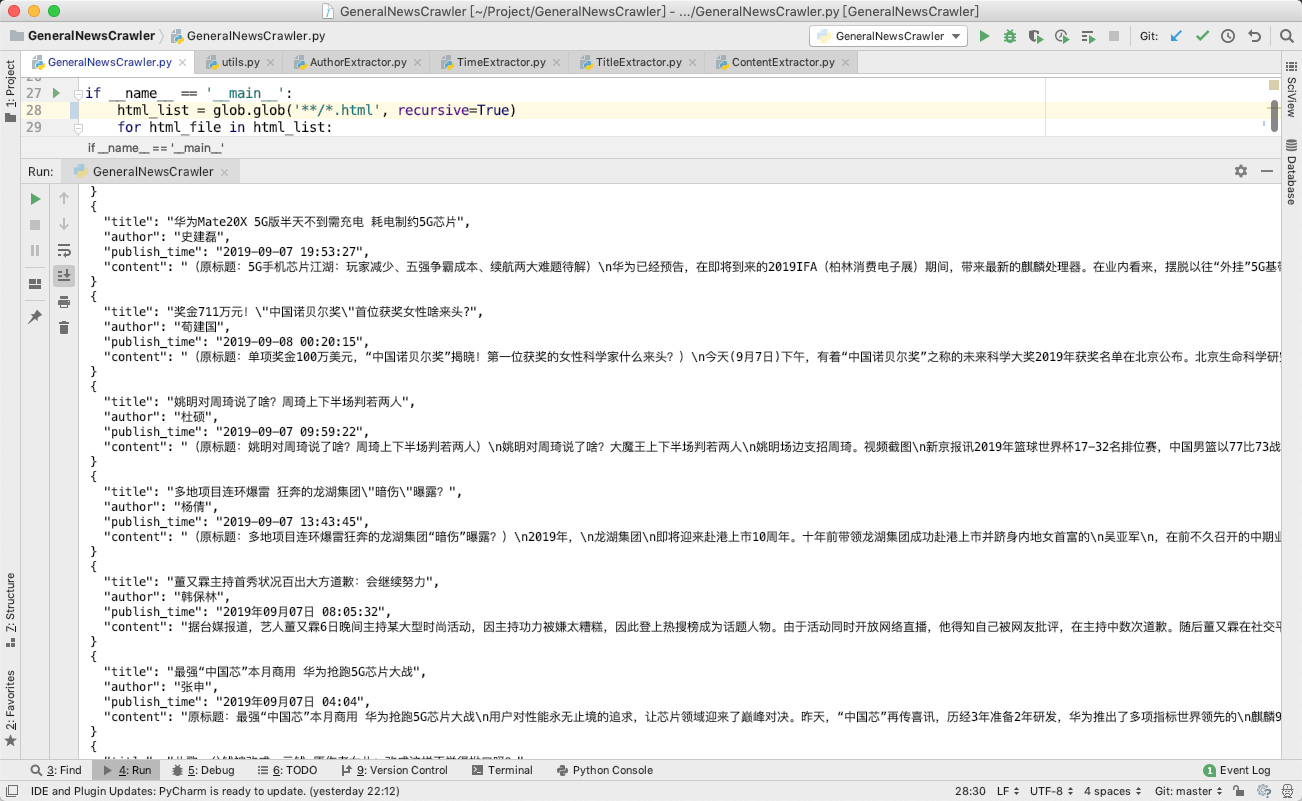
目前这个项目是一个非常非常早期的 Demo,发布出来是希望能够尽快得到大家的使用反馈,从而能够更好地有针对性地进行开发。
本项目取名为抽取器,而不是爬虫,是为了规避不必要的风险,因此,本项目的输入是 HTML,输出是一个字典。请自行使用恰当的方法获取目标网站的 HTML。
本项目现在不会,将来也不会提供主动请求网站 HTML 的功能。
如何使用
项目代码中的GeneralNewsCrawler.py提供了本项目的基本使用示例。
- 本项目的测试代码在
test文件夹中 - 本项目的输入 HTML 为经过 JavaScript 渲染以后的 HTML,而不是普通的网页源代码。所以无论是后端渲染、Ajax 异步加载都适用于本项目。
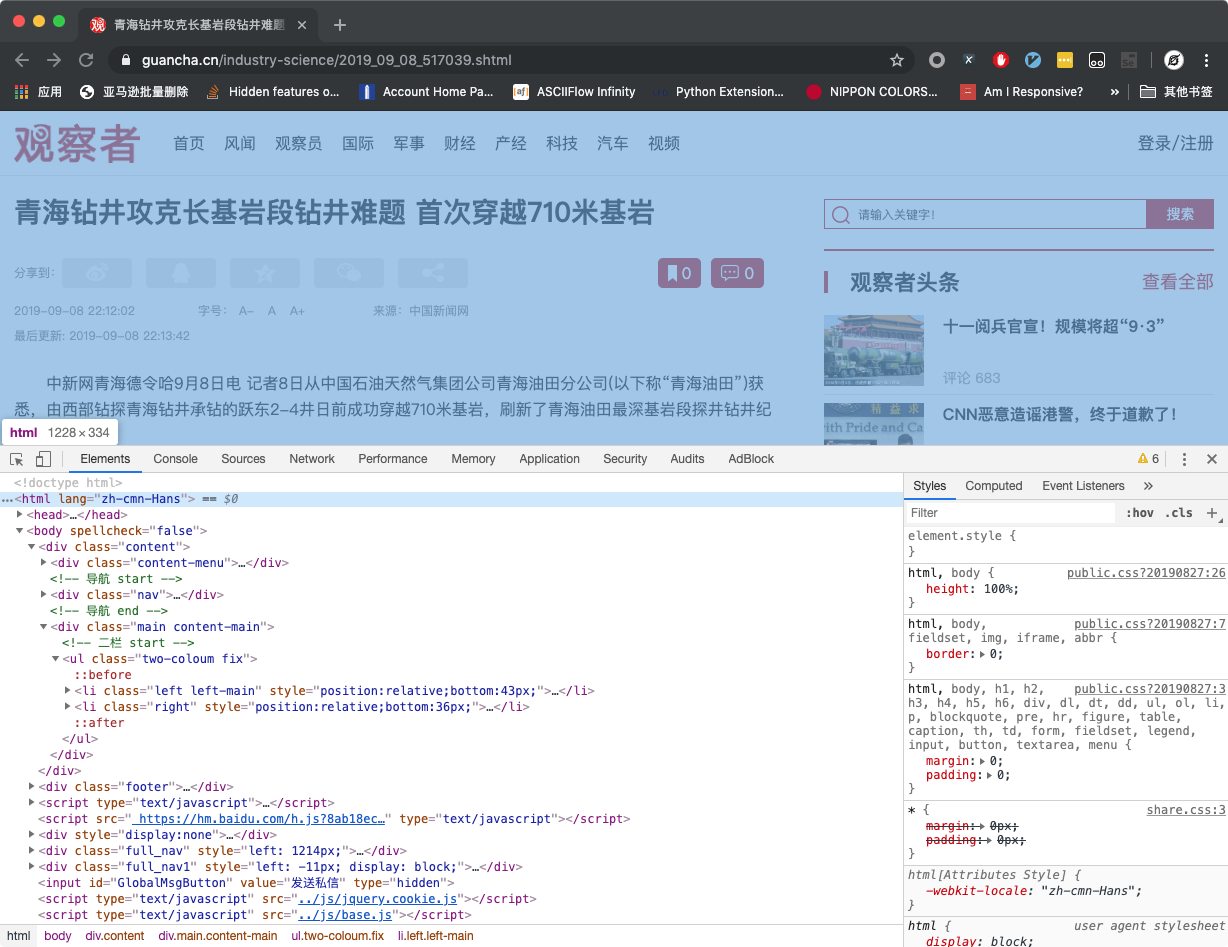
- 如果你要手动测试新的目标网站或者目标新闻,那么你可以在 Chrome 浏览器中打开对应页面,然后开启
开发者工具,如下图所示:
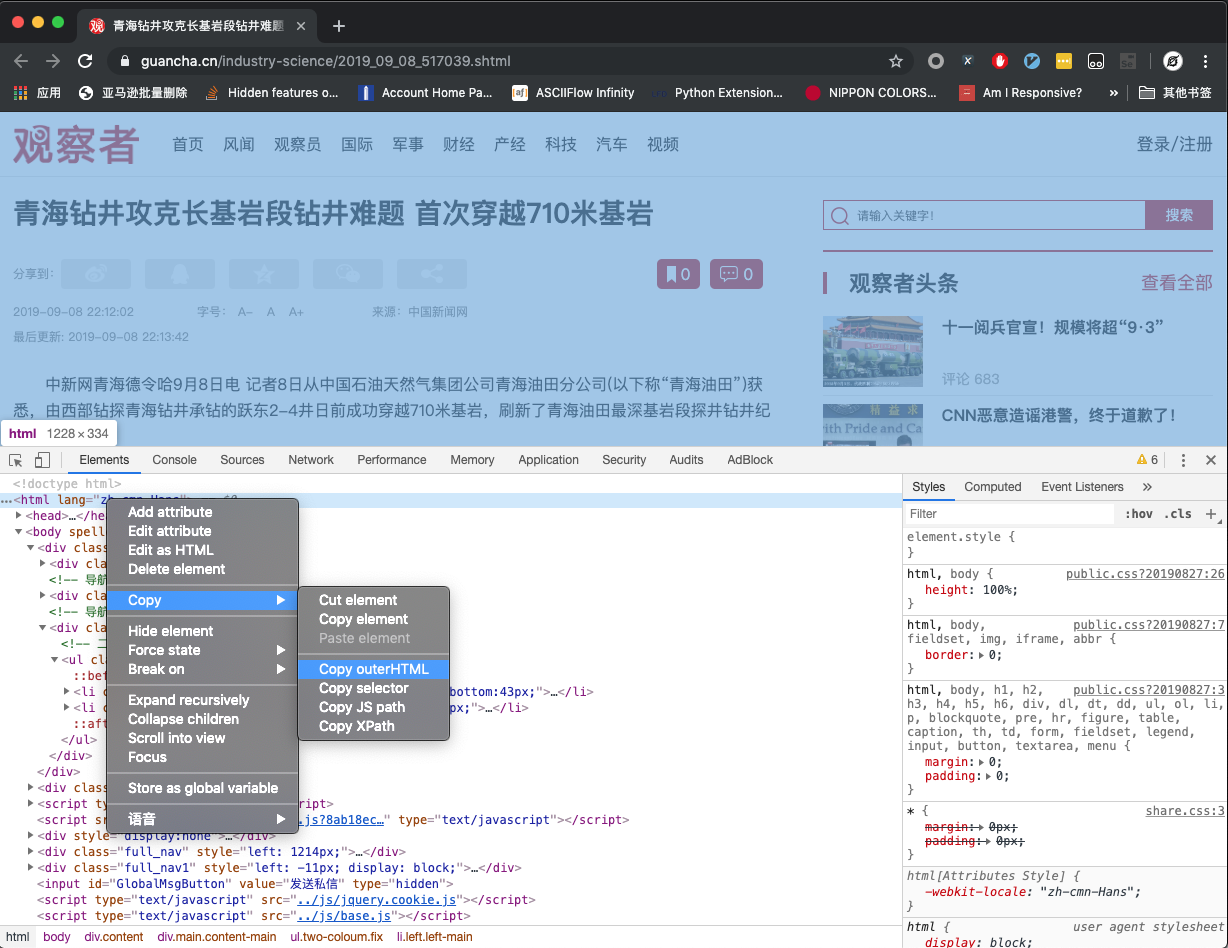
在Elements标签页定位到<html>标签,并右键,选择Copy-Copy OuterHTML,如下图所示
-
当然,你可以使用 Puppeteer/Pyppeteer、Selenium 或者其他任何方式获取目标页面的
JavaScript 渲染后的源代码。 -
获取到源代码以后,通过如下代码提取信息:
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对大多数新闻页面而言,以上的写法就能够解决问题了。
但某些新闻网页下面会有评论,评论里面可能存在长篇大论,它们会看起来比真正的新闻正文更像是正文,因此extractor.extract()方法还有一个默认参数noise_mode_list,用于在网页预处理时提前把评论区域整个移除。
noise_mode_list的值是一个列表,列表里面的每一个元素都是 XPath,对应了你需要提前移除的,可能会导致干扰的目标标签。
例如,观察者网下面的评论区域对应的 Xpath 为//div[@class="comment-list"]。所以在提取观察者网时,为了防止评论干扰,就可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中的网页的提取结果,请查看result.txt。
已知问题
- 目前本项目只适用于新闻页的信息提取。如果目标网站不是新闻页,或者是今日头条中的相册型文章,那么抽取结果可能不符合预期。
- 可能会有一些新闻页面出现抽取结果中的作者为空字符串的情况,这可能是由于文章本身没有作者,或者使用了已有正则表达式没有覆盖到的情况。
Todo
- 使用一个配置文件来存放常量数据,而不是直接 Hard Code 写在代码中。
- 允许自定义时间、作者的提取 Pattern
- 增加新闻列表页的自动提取功能
- 优化内容提取速度
- 测试更多新闻网站
- ……
交流沟通
项目地址:https://github.com/kingname/GeneralNewsExtractor
本项目的交流微信群:

第 1 条附言 · 2019-09-09 12:47:42 +08:00
入群二维码已经满了,
请扫描下面的二维码加我:

备注消息:GNE进群。
 |
1
itskingname OP 怎么都是收藏,没有评价的
|
 |
2
lsvih 2019-09-09 11:14:32 +08:00
论文方法和《基于行块分布函数的通用网页正文抽取算法》的思想基本一样,但是没有引用和对比这篇文章。
|
 |
3
tlemar 2019-09-09 11:18:16 +08:00
> 本项目取名为抽取器,而不是爬虫,是为了规避不必要的风险,因此,本项目的输入是 HTML,输出是一个字典。请自行使用恰当的方法获取目标网站的 HTML。 本项目现在不会,将来也不会提供主动请求网站 HTML 的功能。
爬虫已经这么危险了么。 |

|
5
itskingname OP @tlemar 安全第一
|
 |
6
yuanfnadi 2019-09-09 11:49:41 +08:00
|
|
7
itskingname OP @lsvih 你觉得哪个方法更好
|
|
8
itskingname OP @yuanfnadi 它的速度太慢了
|
 |
9
zhuangjia 2019-09-09 11:52:45 +08:00
先收藏了,后面有时间跑一下看看效果。-_-
|
|
10
yuanfnadi 2019-09-09 11:53:04 +08:00
@itskingname 能分享一下论文吗。
|
 |
11
deepall 2019-09-09 11:53:57 +08:00
Readability 的效果并不怎么好
|
|
12
yuanfnadi 2019-09-09 12:00:58 +08:00
看了一下论文的实现
将网页中的 html 标签全部去掉,再去掉空白行和空白部分,得到文本。 这样只适合新闻文章,不适合有代码块的技术文章。 |
|
13
deepall 2019-09-09 12:08:19 +08:00
人家都说了新闻类网页
|
 |
14
guyskk0x0 2019-09-09 12:24:45 +08:00 via Android
收藏了。请问性能有什么特别的优化吗,平均处理一个网页要多少毫秒?
|
|
15
itskingname OP @yuanfnadi 我对论文里面的算法做了修改。
|
|
16
itskingname OP @guyskk0x0 这是早期版本,会先专注于完善功能,然后再优化性能。请持续关注。
|
 |
17
googlefans 2019-09-09 13:56:16 +08:00
@itskingname 今天看见有人推了
|
|
18
itskingname OP @googlefans 在哪里推的
|

 |
20
Chappako 2019-09-09 16:39:25 +08:00
收藏并 Star 了,持续关注,改天测试一下
|
|
21
itskingname OP @Chappako 感谢~你可以现在测试一下,搭建环境并运行测试样例只需要 1 分钟。
|

|
23
lsvih 2019-09-09 17:53:54 +08:00
|
|
24
itskingname OP @lsvih 求提供 bad case
|
 |
25
exip 2019-09-09 20:03:22 +08:00 via Android
先收藏,晚点要用
|
|
26
itskingname OP @exip 现在就可以用
|
 |
27
xiaotuzi 2019-09-09 22:20:20 +08:00 via iPhone
看看 php simple html dom,这早就有了,你现在才开始发现???其实就是 xpath,PHP 有支持 xpath
|
|
28
itskingname OP @xiaotuzi 不是
|
|
29
itskingname OP 收藏比评论多。
|
 |
30
dicc 2019-09-11 08:55:11 +08:00
我的爬虫都是快照形式, css, js 全都抓下来了, 打开就是原样网页
|